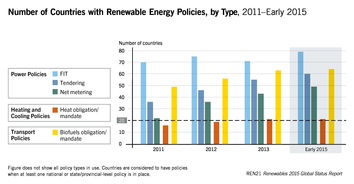
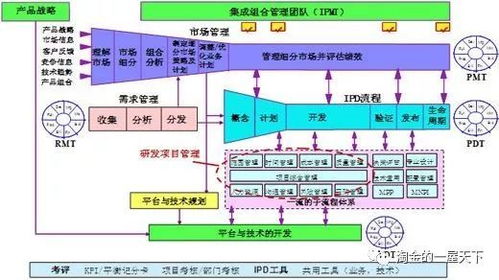
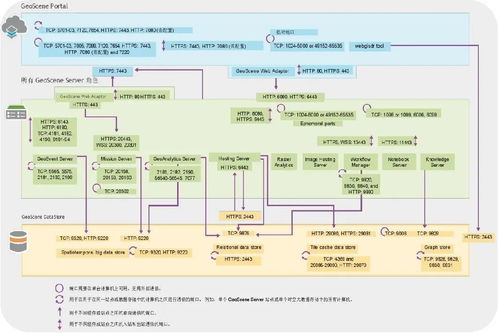
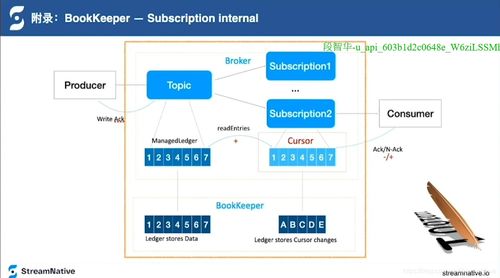
在能源轉(zhuǎn)型與可持續(xù)發(fā)展的全球背景下,生物質(zhì)能作為一種重要的可再生能源,其資源信息的有效管理與利用變得至關(guān)重要。傳統(tǒng)的生物質(zhì)能資源信息往往分散于海量的科技文獻(xiàn)、研究報(bào)告、政策文件和產(chǎn)業(yè)數(shù)據(jù)中,信息提取效率低、整合難度大,嚴(yán)重制約了資源評(píng)估與產(chǎn)業(yè)規(guī)劃。為此,構(gòu)建一個(gè)集成化、智能化的生物質(zhì)能資源數(shù)據(jù)庫(kù)信息系統(tǒng),并利用人工智能技術(shù)進(jìn)行高效的信息抽取,成為一個(gè)極具價(jià)值的機(jī)器學(xué)習(xí)應(yīng)用項(xiàng)目。
一、 項(xiàng)目目標(biāo)與核心價(jià)值
本項(xiàng)目的核心目標(biāo)是開發(fā)一個(gè)能夠自動(dòng)、精準(zhǔn)地從多源異構(gòu)數(shù)據(jù)中抽取關(guān)鍵生物質(zhì)能資源信息,并將其結(jié)構(gòu)化整合到統(tǒng)一數(shù)據(jù)庫(kù)中的智能系統(tǒng)。其核心價(jià)值在于:
- 提升信息獲取效率:通過(guò)AI自動(dòng)化處理,將人力從繁瑣的信息篩查與錄入工作中解放出來(lái),大幅縮短數(shù)據(jù)采集周期。
- 保證數(shù)據(jù)質(zhì)量與一致性:利用機(jī)器學(xué)習(xí)模型統(tǒng)一信息抽取標(biāo)準(zhǔn),減少人為誤差,形成標(biāo)準(zhǔn)化、高質(zhì)量的數(shù)據(jù)集。
- 深度挖掘數(shù)據(jù)關(guān)聯(lián):通過(guò)對(duì)抽取的結(jié)構(gòu)化信息進(jìn)行分析,可以發(fā)現(xiàn)資源分布規(guī)律、技術(shù)發(fā)展趨勢(shì)、產(chǎn)業(yè)鏈關(guān)聯(lián)等深層知識(shí)。
- 支撐科學(xué)決策與創(chuàng)新:為政府部門的資源規(guī)劃、科研機(jī)構(gòu)的技術(shù)研發(fā)、企業(yè)的投資與生產(chǎn)提供全面、實(shí)時(shí)、可靠的數(shù)據(jù)支持。
二、 人工智能輔助信息抽取的關(guān)鍵技術(shù)
信息抽取是連接非結(jié)構(gòu)化文本與結(jié)構(gòu)化數(shù)據(jù)庫(kù)的橋梁。本項(xiàng)目將綜合利用以下機(jī)器學(xué)習(xí)與自然語(yǔ)言處理技術(shù):
- 命名實(shí)體識(shí)別:這是信息抽取的基石。通過(guò)訓(xùn)練特定的NER模型,系統(tǒng)能夠從文本中自動(dòng)識(shí)別并分類出與生物質(zhì)能相關(guān)的實(shí)體,例如:
- 資源實(shí)體:秸稈、林木廢棄物、藻類、城市有機(jī)垃圾等。
- 技術(shù)實(shí)體:氣化、厭氧消化、直接燃燒、熱解等。
- 屬性實(shí)體:熱值、含水率、產(chǎn)量、地理位置等。
- 數(shù)值與單位實(shí)體:用于量化資源潛力與技術(shù)參數(shù)。
- 關(guān)系抽取:在識(shí)別實(shí)體的基礎(chǔ)上,進(jìn)一步判斷實(shí)體之間的關(guān)系。例如,從“某地區(qū)年產(chǎn)水稻秸稈1000萬(wàn)噸”這句話中,抽取出“(地區(qū),資源類型,年產(chǎn)量)”的三元組關(guān)系。這對(duì)于構(gòu)建知識(shí)圖譜至關(guān)重要。
- 事件抽取:用于捕捉動(dòng)態(tài)信息,如政策發(fā)布、技術(shù)突破、項(xiàng)目投產(chǎn)等。例如,抽取“某公司于2023年建成一座年處理10萬(wàn)噸秸稈的生物質(zhì)發(fā)電廠”這一事件的主體、時(shí)間、地點(diǎn)和關(guān)鍵參數(shù)。
- 文本分類與過(guò)濾:首先對(duì)海量文檔進(jìn)行自動(dòng)分類(如分為科研論文、產(chǎn)業(yè)報(bào)告、政策文件等),并過(guò)濾掉不相關(guān)的文檔,提高后續(xù)處理的針對(duì)性。
- 領(lǐng)域自適應(yīng)與少樣本學(xué)習(xí):生物質(zhì)能領(lǐng)域?qū)I(yè)性強(qiáng),公開標(biāo)注數(shù)據(jù)稀缺。項(xiàng)目需采用遷移學(xué)習(xí)、預(yù)訓(xùn)練語(yǔ)言模型微調(diào)(如BERT、ERNIE等在能源領(lǐng)域的微調(diào))以及主動(dòng)學(xué)習(xí)等策略,以有限的標(biāo)注數(shù)據(jù)訓(xùn)練出高性能模型。
三、 生物質(zhì)能資源數(shù)據(jù)庫(kù)信息系統(tǒng)的架構(gòu)設(shè)計(jì)
系統(tǒng)采用分層架構(gòu),確保可擴(kuò)展性與易維護(hù)性:
- 數(shù)據(jù)采集層:負(fù)責(zé)從互聯(lián)網(wǎng)、學(xué)術(shù)數(shù)據(jù)庫(kù)、企業(yè)內(nèi)部系統(tǒng)等渠道自動(dòng)爬取和接入多源數(shù)據(jù),包括文本、表格、PDF、圖片(需OCR識(shí)別)等。
- AI處理引擎層(核心):
- 預(yù)處理模塊:進(jìn)行文本清洗、分詞、格式標(biāo)準(zhǔn)化等。
- 信息抽取模塊:集成上述NER、關(guān)系抽取、事件抽取等模型,對(duì)文本進(jìn)行深度解析,輸出結(jié)構(gòu)化數(shù)據(jù)(JSON或關(guān)系型數(shù)據(jù))。
- 質(zhì)量校驗(yàn)?zāi)K:通過(guò)規(guī)則校驗(yàn)、置信度評(píng)估、人工復(fù)核接口等方式,確保抽取結(jié)果的準(zhǔn)確性。
- 數(shù)據(jù)存儲(chǔ)與管理層:
- 核心數(shù)據(jù)庫(kù):采用關(guān)系型數(shù)據(jù)庫(kù)存儲(chǔ)高度結(jié)構(gòu)化的資源屬性、技術(shù)參數(shù)、項(xiàng)目信息等。
- 知識(shí)圖譜庫(kù):使用圖數(shù)據(jù)庫(kù)存儲(chǔ)實(shí)體及其復(fù)雜關(guān)系,便于進(jìn)行關(guān)聯(lián)查詢和推理分析。
- 文檔庫(kù):存儲(chǔ)原始文檔及抽取過(guò)程的元數(shù)據(jù),以備溯源。
- 應(yīng)用服務(wù)與展示層:
- API接口:為第三方應(yīng)用提供數(shù)據(jù)查詢與訂閱服務(wù)。
- 可視化分析平臺(tái):提供交互式儀表盤,支持資源地圖分布、時(shí)間趨勢(shì)分析、技術(shù)對(duì)比、潛力評(píng)估等功能。
- 數(shù)據(jù)檢索與導(dǎo)出:支持用戶進(jìn)行多維度、組合條件的精確檢索,并導(dǎo)出所需數(shù)據(jù)。
四、 項(xiàng)目實(shí)施挑戰(zhàn)與展望
主要挑戰(zhàn)包括:領(lǐng)域?qū)I(yè)術(shù)語(yǔ)的準(zhǔn)確識(shí)別、多語(yǔ)言和跨文化數(shù)據(jù)源的處理、非結(jié)構(gòu)化數(shù)據(jù)(如報(bào)告中的圖表)的信息提取、以及系統(tǒng)的持續(xù)迭代與模型更新。
未來(lái)展望,該系統(tǒng)可以進(jìn)一步與物聯(lián)網(wǎng)技術(shù)結(jié)合,接入實(shí)時(shí)的生物質(zhì)資源產(chǎn)生與收集數(shù)據(jù);利用強(qiáng)化學(xué)習(xí)優(yōu)化資源物流路徑;并最終發(fā)展為集“資源監(jiān)測(cè)-評(píng)估-規(guī)劃-交易”于一體的智能決策支持平臺(tái),為全球生物質(zhì)能的規(guī)模化、高效化利用貢獻(xiàn)核心數(shù)據(jù)動(dòng)力。
這個(gè)以人工智能輔助信息抽取為核心的機(jī)器學(xué)習(xí)項(xiàng)目,不僅是構(gòu)建生物質(zhì)能資源數(shù)據(jù)庫(kù)信息系統(tǒng)的技術(shù)引擎,更是推動(dòng)整個(gè)行業(yè)向數(shù)據(jù)驅(qū)動(dòng)、智能決策模式轉(zhuǎn)型升級(jí)的關(guān)鍵基礎(chǔ)設(shè)施。